

I mandags valgte den kunstige intelligens fra AI Alpha Lab aktien Carnival Corp til sin portefølje. Aktien er siden steget over 6%.
Porteføljen og de enkelte aktier kan ses og følges hver uge, hvis du er abonnent hos daytrader.dk. Men hvordan vælger den kunstige intelligens fra AI Alpha Lab egentlig sine aktier? Det handler denne artikel om.
| Om AI Alpha Lab
AI Alpha Lab er grundlagt i 2019 og arbejder for at bygge bro mellem investorer og teknologi med en AI investeringsmodel baseret på beregnede sandsynligheder. De er pionerer inden for brugen af AI på investeringsområdet og gør som nogle af de eneste i Europa en gennemtestet og valideret AI-model tilgængelig for private investorer. Her på daytrader.dk kan du abonnere på to af deres amerikanske porteføljer, ligesom de i slutningen af 2023 lancerede en global investeringsforening, hvor aktierne vælges af deres sandsynlighedsbaserede AI-model. Selv om foreningen er helt ny, har den på rekordtid tiltrukket en masse investorer og på godt 3 måneder rundet 1.600 investorer. Du kan læse mere om foreningen på deres hjemmeside eller investere i den hos fx Nordnet. |
Baysiansk machine learning – sådan vælges aktierne hos AI Alpha Lab
Af AI Alpha Lab
I en af vores tidligere artikler satte vi fokus på, at man for at træffe optimale beslutninger under usikkerhed, som fx investeringsbeslutninger, har brug for et fremtidigt scenarie (afkastforventningen til en aktie) og den tilhørende sandsynlighed for dets realisering.
Beregningen af sandsynligheden består af summen af to typer usikkerhed, datausikkerhed og modelusikkerhed. Datausikkerhed har vi kunnet kvantificere op til i dag, men derimod ikke modelusikkerhed. Det involverer beregningen af alle de mulige modelspecifikationer, der er i stand til at forklare et givent datasæt, for at finde sandsynligheden for, at den valgte model er den rigtige. Baysianske machine learning modeller har gjort os i stand til netop det, men hvorfor er det egentlig?
For at forstå det, er man nødt til at gå et spadestik dybere og kigge på Bayes formel samt begrebet maximum likelihood, fordansket oversat til maksimal sandsynlighed. Det prøver vi at gøre i denne artikel. Det kan godt gå hen og blive en smule teknisk, men vi har gjort vores bedste for at holde benene på jorden.
Bayes formel
Nedenfor ses Bayes formel, der er en måde at udføre korrekt hypotesetestning på, når man står over for usikkerhed. Selvom mange inden for natur- og samfundsvidenskaberne er enige om, at dette er den rigtige måde at observere den fysiske virkelighed, vi lever i, på, har der historisk set været to problemer med formlen.
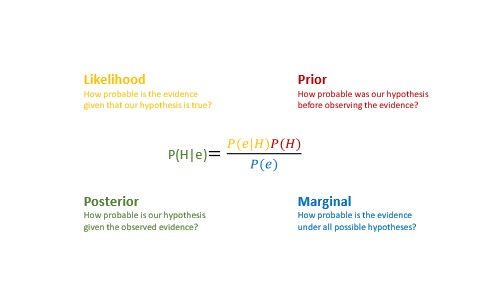
Det første problem er prior knowledge (rød). Indarbejdelse af prior knowledge kræver, at videnskabsmænd skal blive enige om og formalisere deres viden. Det er en svær opgave. Det andet problem er den marginale sandsynlighed (blå). Den kræver estimering af alle mulige hypoteser eller modeller givet de observerede data. En eksponentielt vanskelig estimeringsprocedure med potentielt milliarder af parametre at estimere.
Løsningen på de to problemer blev naivt at antage, at vi ingen prior knowledge har om de problemer, vi forsøger at løse, og at undlade at behandle problemer i marginale sandsynligheder. Dermed er det eneste, som er tilbage på højre side af Bayes formel, sandsynligheden givet data. Dvs. at som sådan kan vi udlede ting om verden ved kun at beregne den maksimale sandsynlighed (maximum likelihood) ud fra det data, vi kigger på. Det er åbenlyst, at for at nå til den konklusion, har vi lavet en masse tvivlsomme antagelser!
Maximum likelihood
Maximum likelihood betyder basalt set en procedure, der på bedste vis tilpasser parametrene for en model til et givet datasæt. Dette er problematisk, når de data, der bruges til tilpasningen, er forskellige fra de data, modellen skal forklare. Det kan fx være finansielle data, der er dynamiske, og derfor i mange tilfælde ikke er en god repræsentation af fremtiden.
Maximum likelihood-modellerne inkorporerer ikke nogen prior knowledge, som vi måtte have, og samtidig er modellen tvunget til at finde den bedste tilpasning. Dette gør maximum likelihood-modeller tilbøjelige til at finde tilfældige sammenhænge og ikke kausalitet.
Nøglen til at løse dette problem ligger i konceptet Bayesiansk machine learning, der kombinerer data, domæneviden og probabilistisk modellering. Ved at inkorporere prior knowledge om det aktuelle problem, kode det som en statistisk fordeling og derefter kombinere det med informationen i data, reducerer man risikoen for at tilpasse modellen til statistiske sandheder (hypotese generering og ikke hypotese validering).
Derudover tillader Bayesiansk machine learning modellen at tvivle på sine konklusioner, hvilket tvinger den til at se bort fra falske korrelationer og kvantificere gyldigheden af dens forudsigelser. Kombinationen af alt dette resulterer i en model, der faktisk har en forståelse af det miljø, den opererer i.
For at høste fordelene ved machine learning skal vi som mennesker være smarte i vores brug af dette kraftfulde værktøj. De fleste populære modeller fra machine learning i dag, som fx neurale netværk, tilpasser blot en linje til eksisterende data, dvs. en avanceret lineær regression.
Uanset hvor komplekst eller dybt netværket er, gør netværket præcis det samme. Du kan konfigurere netværket anderledes for at få repræsentationer i forskellige lag og gøre det mere effektivt, men det afgørende er, hvorledes modellen skal forholde sig til det data, den trænes på, samt de variable, den skal forsøge at forklare. Er disse statiske eller varierende? En simpel machine learning model giver dig kun ét svar, der passer til din model, uden at sætte spørgsmålstegn ved den. Helt ligesom klassiske maximum likelihood-modeller.
Hvad du kan gøre med Bayesianske prædiktive inferensmaskiner, der bruger probabilistisk programmering, er at give algoritmen plads til tvivl og mulighed for, at modellen kan modbevise din antagelse. På den måde minimerer vi risikoen for at tilpasse vores model til den falske korrelation i data og maksimerer sandsynligheden for, at vi tilpasser vores model til sande årsagssammenhænge svarende til den fysiske virkelighed, vi lever i.

Den nye doktrin
Matematikere, statistikere, fysikere og professionelle investorer er blevet indoktrineret med modeller, der aldrig var beregnet til at løse komplekse problemer i det virkelige liv. Modeller, der var afhængige af strenge antagelser for at passe til en virkelighed, der aldrig har eksisteret, men indtil nu var dette berettiget, da der ikke var noget alternativ. Det er der i dag!
Baysiansk machine learning giver os muligheden for at træffe optimale beslutninger i en verden af usikkerhed. I dag kan vi modellere verden uden at stole på urealistiske antagelser, der resulterer i statistiske resultater fremfor kausalitet.
Ja, investorer er tvunget til at træde ud i ukendt farvand, uddanne sig inden for områder, der ikke tidligere var påkrævet af finansverdenen og acceptere, at computere nu kan løse visse opgaver meget bedre end mennesker. Men vi i AI Alpha Lab tror, at de der tager springet, uddanner sig selv og inkorporerer Baysiansk machine learning vil blive belønnet. De vil være på forkant med aktiv investering i de kommende årtier, kunne tage mere informerede investeringsbeslutninger og være bevæbnet med viden om, hvad de ikke ved.
Læs med i vores næste blog når vi viser, at en usikkerhedsmodel gør dig i stand til at investere som en taber – og hvorfor det er en god ting!
“It ain’t what you don’t know that gets you into trouble.
It’s what you know for sure that just ain’t so.”
– Mark Twain
Disclaimer
Denne artikel er udarbejdet af AI Alpha Lab ApS (AI Alpha Lab) og indeholder alene information og inspiration til læseren. Artiklen skal ikke betragtes som investeringsrådgivning og kan ikke påberåbes som grundlag for en beslutning om køb eller salg (eller undladelse heraf) af værdipapirer. AI Alpha Lab påtager sig ikke noget ansvar for beslutninger eller dispositioner, der træffes eller foretages på baggrund af oplysninger i artiklen.
Artiklen udgør ikke og skal ikke betragtes som et tilbud eller en opfordring til at gøre tilbud eller til at deltage i eller udføre bestemte investeringer. Omtales investeringsstrategier eller porteføljer af værdipapirer skal læseren være opmærksom på, at disse ikke nødvendigvis er fordelagtige for alle investorer, samt at AI Alpha Lab ikke kender den enkelte læsers individuelle økonomiske forhold, risikopræferencer, investeringserfaring m.m.
AI Alpha Lab har taget alle rimelige forholdsregler for at sikre rigtigheden og nøjagtigheden af oplysningerne i artiklen, ligesom artiklen er baseret på oplysninger indhentet fra kilder, der menes at være pålidelige. Rigtigheden og nøjagtigheden er dog ikke garanteret, og AI Alpha Lab påtager sig intet ansvar for eventuelle fejl eller udeladelser.
Oplysningerne i artiklen afgives på dagen for offentliggørelsen og opdateres eller ændres ikke efterfølgende, medmindre andet tydeligt fremgår. Læseren opfordres til at søge individuel rådgivning om egne investeringsforhold.